이 글에서 얻을 수 있는 정보
- 스프링 배치가 무엇이고, 작동원리가 무엇인지
- 배치를 더욱 빨리 처리하려면 어떻게 해야하는지
spring batch란 ?
-
어플리케이션을 운영하다보면 사용자와의 상호작용 없이, 대량의 데이터를 한번에 가공해야할 일이 생긴다. 예를 들어 월초에 사용자의 실적에 따라 등급을 업그레이드하거나, 연말 정산등을 할 때도 한번에 수많은 자료를 일괄적으로 처리해야 한다.
-
그리고 이런 작업은 대부분 반복적으로 수행되며, 레코드를 읽고 → 데이터를 처리하고 → 데이터를 다시 쓰는 비슷한 방식으로 수행된다. 따라서 spring에서는 이러한 기본 배치 반복을 자동화하고, 객체화 하여 사용자가 보다 쉽게 배치 작업을 수행할 수 있도록 했다.
spring batch의 기본 구현 방식
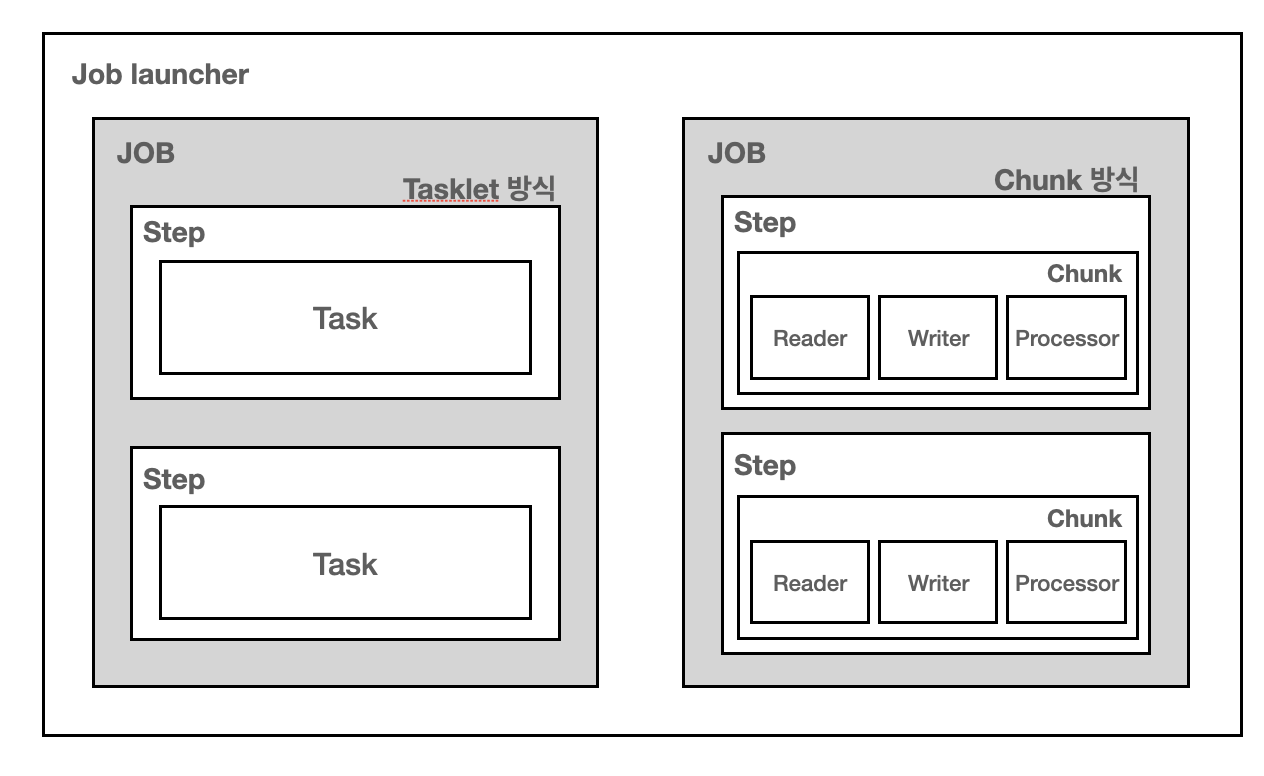
-
Spring batch의 기본 구현 방식은 상단과 같다. Job launcher가 사용자가 명시한 여러가지 Job들을 수행한다. 그리고 JOB은 여러가지의 Step으로 이루어져 있다.
-
유저 등급을 갱신하는 상황을 예시로 들어보면, “매월 1일 유저 등급을 갱신하고, 등급에 따라 쿠폰을 배부한다”가 Job이고, Step1은 “유저 테이블에 등급을 매긴다”, Step2는 “등급에 따라 쿠폰을 배부한다” 가 될 것이다.
그리고 Step을 구현하는 두가지 방식에 대해 알아보자
1️⃣ tasklet 방식
• 하나의 tasklet 내부에서 자유롭게 데이터를 처리한다.
• 배치 과정이 비교적 쉬울 경우 사용한다.
• 대량 처리를 하는 경우에는 코드가 오히려 더 복잡해질 수 있다.
2️⃣ Chunk 방식
• itemReader, itemProcessor, itemWriter에 대해 이해해야 구현할 수 있다.
• 하나의 큰 덩어리를 작은 덩어리로 나누어 처리할 수 있다.
Multi-thread 기반 Spring batch 처리
💡 문제는, 너무 느려 !
-
spring batch의 경우 애초에 대용량의 데이터를 한꺼번에 처리하기 위해 만들어졌으므로, 수많은 레코드들을 한번에 갱신해야 한다. 그런데 문제는 ,, 스프링 배치가 기본적으로 single thread 방식으로 진행된다는 것이다 !
-
하단은 1011개의 데이터를 single-thread 기반으로 처리할 때 걸린 시간을 측정한 것이다. 총 49초가 소요되었음을 알 수 있다..

- 물론 배치 작업이 자주 이루어지지 않거나, 서비스 장애가 크리티컬한 이슈를 만들어내지 않는 환경이라면 굳이 multi-thread 방식을 도입하지 않아도 될 것이다.
-
그러나 자주 배치 작업이 일어나고, 서비스 중단이 유저의 사용성에 큰 영향을 줄 경우 최대한 spring batch에 드는 시간을 줄여야하며, 이 경우 multi-thread 기반 spring batch 처리를 반드시 해야할 것이다 !
마무리
- 이번 포스팅에서는 java spring batch가 무엇인지 알아보고, spring batch를 multi-thread로 처리할 때의 이점에 대해 알아보았다.
- 다음 포스팅에서는 spring batch를 multi-thread로 처리하는 방법에 대해 알아보자 !